Connecting the Dots: Understanding the Insurance Risks of Fronting and Named Drivers
 If we think about fronting or the ghost-broking scandals – fraudsters who sell drivers apparently cheap motor insurance deals but issue fake policy documents, not worth the paper they’re printed on – the insurance industry has room for improvement when it comes to protecting customers, or communicating with them, in these cases.
If we think about fronting or the ghost-broking scandals – fraudsters who sell drivers apparently cheap motor insurance deals but issue fake policy documents, not worth the paper they’re printed on – the insurance industry has room for improvement when it comes to protecting customers, or communicating with them, in these cases.
Our own LexisNexis Risk Solutions research has shown the extent to which large sections of motorists view fraud, and manipulating quotation data, as a victimless crime. We found 35% of consumers believe it is acceptable to misrepresent data in some form in their insurance application or claim.
This 2015 study analysed UK drivers’ attitudes towards fraud, and it also found that 55% of drivers believe an insurer should still pay out on a claim, even once it has been found to have contained false information.
Worrying statistics such as those revealed in our research highlight the increasing importance of verified data in insurance application and claims assessment processes.
Verified data is a vital component in the insurance industry’s ongoing fight against casual motor insurance fraud, as it can help effectively manage risk at the point of underwriting and also help the claims team in identifying fraudulent claims.
How can insurance deal with fronting and bring security to the consumer?
At the lower end of the scale in misrepresenting insurance information comes fronting: when a driver chooses to manipulate the name of the main driver and the named driver on a policy to cut costs. Most frequently fronting is when a young driver sets up their parent, or another older, low-risk driver, as the main driver. For the policyholder it comes with many risks and hidden costs of being caught out in the event of a claim. ActionFraud has described it as a type of insurance fraud and anyone found to be fronting runs the risk of having their coverage cancelled.
LexisNexis Risk Insights and LexisNexis Informed Quotes
Now, with the launch of LexisNexis Risk Insights being delivered through our Informed Quotes platform, we are making useful named driver information available to insurance providers. It’s going to put the insurance industry in a position to connect up the dots on where named drivers appear in the quoting journey.
Quote Intelligence (QI) has been a live service since 2016, but now in combination with Risk Insights, we believe it is going to bring about a powerful change in this area of risk and uncertainty, and with the ability to search the names and address details of up to five individuals at the point of quote.
The Named Driver factors will be an extension to the Quote Intelligence service, using attributes built up over multiple quotes in a 90-day window to verify factors such as:
- Is the surname of proposer equal to the surname of named drivers?
- The number of drivers and how this changes through the quoting journey
- Potential same family relationships between proposer and named drivers
- Maximum/minimum of named drivers who all have the same surname as the proposer
- Maximum/minimum of named drivers who all have different surnames as the proposer
- A potential fronting indicator occurs where the individual has appeared at some point as both the proposer and the named driver on the same vehicle.
How can insurance providers better understand the risk of named drivers?
We have commented in another blog article about the launch of LexisNexis Attract™ and LexisNexis Risk Insights. With LexisNexis Attract™ we are able to match up to 92% of individuals to their motor insurance shopping process. Similarly, when using the policyholder’s address we are able to match up to 92% of named drivers to an individual level. LexisNexis Risk Insights helps insurance providers better assess and validate risk by leveraging proprietary attributes based on a combination of public records information and other insurance-specific data sources, such as policy history.
To understand the scale of the named driver issue, we’ve been pulling out some anonymised examples of data manipulation using named drivers from our databases.
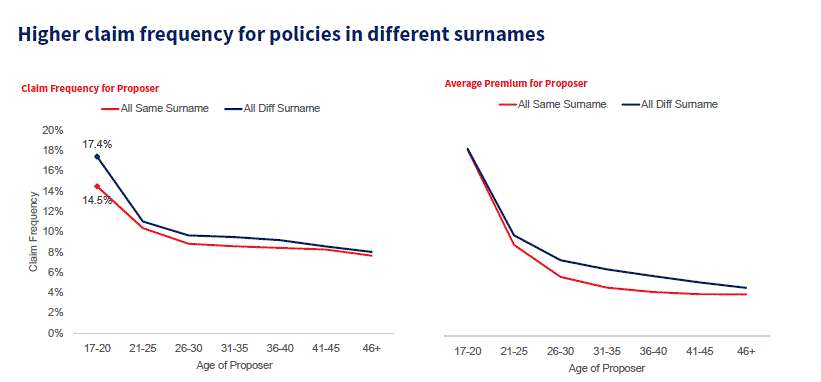
Higher claims frequency for insurance policies combining different surnames
Typically 70% to 80% of drivers in position one of the quote have the same surname as the proposer. There is a higher claims frequency for policies in different surnames, compared to those with the same surname.
The graphic below shows variations in the claims frequencies in relation to the placement of surnames and the age of the proposer.
Case studies on how named drivers appear in the insurance quote journey
The statistics confirm some things we already know about fronting. Connecting the data together enables us to create new risk attributes related to fronting.
Looking at how things change in the quoting journey, named driver attributes are going to bring more accurate pricing for insurers and peace of mind for consumers too.
- Example one: David and John
Day 1: In this real life example, David was the policy holder born 1960 and John the named driver born 1992. The policy was taken out in June 2015 on a vehicle registered at the proposer’s address. Using the Named Driver data block and existing Quote Intelligence (QI) factors we can understand the behaviours prior to the policy being purchased. - Example two: John and Kevin
Day 1: In this example, John, the proposer and Kevin, the named driver appeared on four quotes, all at an address different to the policy. Day 2: Four quotes with a proposer, Karim and John as the named driver. Day 3: Six quotes with John as the proposer on his own, at the policy address. Day four: Four David as policyholder (seen for the first time) and the policy purchased. Following post-inception checks, the policy was cancelled for misrepresentation. - Example three: Leon, Patrick and Joanne
Day 1: Leon, the policyholder born 1958, Patrick 1953 named driver and Joanne, named driver 1972. The policy was taken out in June 2015. Over the course of 26 hours, 16 quotes were requested on the same vehicle. One quote was at a new address, over 40 miles away from the policy address. Two quotes were at a third address, over 50 miles away and one of the named drivers, Patrick, changed to Fitzpatrick. Day 2: Two quotes with Joanne as the proposer. Two quotes with Patrick on his own at a third address. One quote with Leon as policy holder (seen for the first time) and the policy was purchased. The QI service looks back at up to 90 days of quoting history. - Example four: Peter and Matt
Day 1: In this example Peter was the policyholder, born 1958, and Matt was the named driver born 1954. In this case, the address remains the key to tracking the quoting behaviour, tying quotes together with six other vehicles and seven individuals. Peter and Peter Jr interchanged as the proposer on some quotes, with Ian, Matt, Wayne, Adam, Asif, Tony, Frank and Peter Jr appearing as named drivers on the policy file. QI was able to identify that the proposer has appeared as a named driver on a previous quote. Peter Jr appears as both proposer and named driver on a previous quote. The surnames on the policy match. A maximum of three named drivers on a single quote share the same surname as the proposer. Another rating factor is that a maximum of two named drivers on a single quote all have different surnames to the proposer.
By identifying these types of named driver attributes, insurance providers are able to start looking at fronting and suspicious behaviour in a way that has not been possible before.
There are several ways we at LexisNexis Risk Solutions can deliver the Named Driver factors into the insurance workflow: as risk attributes, or with the scorecard method as a score, or feeding into an existing score.
Follow the link to the LexisNexis Risk Solutions website to find out more about how we support insurers.